
1.4. Nearest Neighbors¶
sklearn.neighbors provides functionality for unsupervised and supervised neighbors-based learning methods. Unsupervised nearest neighbors is the foundation of many other learning methods, notably manifold learning and spectral clustering. Supervised neighbors-based learning comes in two flavors: classification for data with discrete labels, and regression for data with continuous labels.
The principle behind nearest neighbor methods is to find a predefined number of training samples closest in distance to the new point, and predict the label from these. The number of samples can be a user-defined constant (k-nearest neighbor learning), or vary based on the local density of points (radius-based neighbor learning). The distance can, in general, be any metric measure: standard Euclidean distance is the most common choice. Neighbors-based methods are known as non-generalizing machine learning methods, since they simply “remember” all of its training data (possibly transformed into a fast indexing structure such as a Ball Tree or KD Tree.).
Despite its simplicity, nearest neighbors has been successful in a large number of classification and regression problems, including handwritten digits or satellite image scenes. Being a non-parametric method, it is often successful in classification situations where the decision boundary is very irregular.
The classes in sklearn.neighbors can handle either Numpy arrays or scipy.sparse matrices as input. For dense matrices, a large number of possible distance metrics are supported. For sparse matrices, arbitrary Minkowski metrics are supported for searches.
There are many learning routines which rely on nearest neighbors at their core. One example is kernel density estimation, discussed in the density estimation section.
1.4.1. Unsupervised Nearest Neighbors¶
NearestNeighbors implements unsupervised nearest neighbors learning. It acts as a uniform interface to three different nearest neighbors algorithms: BallTree, KDTree, and a brute-force algorithm based on routines in sklearn.metrics.pairwise. The choice of neighbors search algorithm is controlled through the keyword 'algorithm', which must be one of ['auto', 'ball_tree', 'kd_tree', 'brute']. When the default value 'auto' is passed, the algorithm attempts to determine the best approach from the training data. For a discussion of the strengths and weaknesses of each option, see Nearest Neighbor Algorithms.
Warning
Regarding the Nearest Neighbors algorithms, if two neighbors, neighbor k+1 and k, have identical distances but but different labels, the results will depend on the ordering of the training data.
1.4.1.1. Finding the Nearest Neighbors¶
For the simple task of finding the nearest neighbors between two sets of data, the unsupervised algorithms within sklearn.neighbors can be used:
>>> from sklearn.neighbors import NearestNeighbors
>>> import numpy as np
>>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
>>> nbrs = NearestNeighbors(n_neighbors=2, algorithm='ball_tree').fit(X)
>>> distances, indices = nbrs.kneighbors(X)
>>> indices
array([[0, 1],
[1, 0],
[2, 1],
[3, 4],
[4, 3],
[5, 4]]...)
>>> distances
array([[ 0. , 1. ],
[ 0. , 1. ],
[ 0. , 1.41421356],
[ 0. , 1. ],
[ 0. , 1. ],
[ 0. , 1.41421356]])
Because the query set matches the training set, the nearest neighbor of each point is the point itself, at a distance of zero.
It is also possible to efficiently produce a sparse graph showing the connections between neighboring points:
>>> nbrs.kneighbors_graph(X).toarray()
array([[ 1., 1., 0., 0., 0., 0.],
[ 1., 1., 0., 0., 0., 0.],
[ 0., 1., 1., 0., 0., 0.],
[ 0., 0., 0., 1., 1., 0.],
[ 0., 0., 0., 1., 1., 0.],
[ 0., 0., 0., 0., 1., 1.]])
Our dataset is structured such that points nearby in index order are nearby in parameter space, leading to an approximately block-diagonal matrix of K-nearest neighbors. Such a sparse graph is useful in a variety of circumstances which make use of spatial relationships between points for unsupervised learning: in particular, see sklearn.manifold.IsoMap, sklearn.manifold.LocallyLinearEmbedding, and sklearn.cluster.SpectralClustering.
1.4.1.2. KDTree and BallTree Classes¶
Alternatively, one can use the KDTree or BallTree classes directly to find nearest neighbors. This is the functionality wrapped by the NearestNeighbors class used above. The Ball Tree and KD Tree have the same interface; we’ll show an example of using the KD Tree here:
>>> from sklearn.neighbors import KDTree
>>> import numpy as np
>>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
>>> kdt = KDTree(X, leaf_size=30, metric='euclidean')
>>> kdt.query(X, k=2, return_distance=False)
array([[0, 1],
[1, 0],
[2, 1],
[3, 4],
[4, 3],
[5, 4]]...)
Refer to the KDTree and BallTree class documentation for more information on the options available for neighbors searches, including specification of query strategies, of various distance metrics, etc. For a list of available metrics, see the documentation of the DistanceMetric class.
1.4.2. Nearest Neighbors Classification¶
Neighbors-based classification is a type of instance-based learning or non-generalizing learning: it does not attempt to construct a general internal model, but simply stores instances of the training data. Classification is computed from a simple majority vote of the nearest neighbors of each point: a query point is assigned the data class which has the most representatives within the nearest neighbors of the point.
scikit-learn implements two different nearest neighbors classifiers:
KNeighborsClassifier implements learning based on the 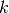 nearest neighbors of each query point, where is an integer value
specified by the user. RadiusNeighborsClassifier implements learning
based on the number of neighbors within a fixed radius
nearest neighbors of each query point, where is an integer value
specified by the user. RadiusNeighborsClassifier implements learning
based on the number of neighbors within a fixed radius  of each
training point, where is a floating-point value specified by
the user.
of each
training point, where is a floating-point value specified by
the user.
The -neighbors classification in KNeighborsClassifier
is the more commonly used of the two techniques. The
optimal choice of the value is highly data-dependent: in general
a larger suppresses the effects of noise, but makes the
classification boundaries less distinct.
In cases where the data is not uniformly sampled, radius-based neighbors
classification in RadiusNeighborsClassifier can be a better choice.
The user specifies a fixed radius , such that points in sparser
neighborhoods use fewer nearest neighbors for the classification. For
high-dimensional parameter spaces, this method becomes less effective due
to the so-called “curse of dimensionality”.
The basic nearest neighbors classification uses uniform weights: that is, the value assigned to a query point is computed from a simple majority vote of the nearest neighbors. Under some circumstances, it is better to weight the neighbors such that nearer neighbors contribute more to the fit. This can be accomplished through the weights keyword. The default value, weights = 'uniform', assigns uniform weights to each neighbor. weights = 'distance' assigns weights proportional to the inverse of the distance from the query point. Alternatively, a user-defined function of the distance can be supplied which is used to compute the weights.


Examples:
- Nearest Neighbors Classification: an example of classification using nearest neighbors.
1.4.3. Nearest Neighbors Regression¶
Neighbors-based regression can be used in cases where the data labels are continuous rather than discrete variables. The label assigned to a query point is computed based the mean of the labels of its nearest neighbors.
scikit-learn implements two different neighbors regressors:
KNeighborsRegressor implements learning based on the
nearest neighbors of each query point, where is an integer
value specified by the user. RadiusNeighborsRegressor implements
learning based on the neighbors within a fixed radius of the
query point, where is a floating-point value specified by the
user.
The basic nearest neighbors regression uses uniform weights: that is, each point in the local neighborhood contributes uniformly to the classification of a query point. Under some circumstances, it can be advantageous to weight points such that nearby points contribute more to the regression than faraway points. This can be accomplished through the weights keyword. The default value, weights = 'uniform', assigns equal weights to all points. weights = 'distance' assigns weights proportional to the inverse of the distance from the query point. Alternatively, a user-defined function of the distance can be supplied, which will be used to compute the weights.

The use of multi-output nearest neighbors for regression is demonstrated in Face completion with a multi-output estimators. In this example, the inputs X are the pixels of the upper half of faces and the outputs Y are the pixels of the lower half of those faces.

Examples:
- Nearest Neighbors regression: an example of regression using nearest neighbors.
- Face completion with a multi-output estimators: an example of multi-output regression using nearest neighbors.
1.4.4. Nearest Neighbor Algorithms¶
1.4.4.1. Brute Force¶
Fast computation of nearest neighbors is an active area of research in
machine learning. The most naive neighbor search implementation involves
the brute-force computation of distances between all pairs of points in the
dataset: for  samples in
samples in  dimensions, this approach scales
as
dimensions, this approach scales
as ![O[D N^2]](../_images/math/f07c5549e04ede6a427992db34661a420ae6c49e.png) . Efficient brute-force neighbors searches can be very
competitive for small data samples.
However, as the number of samples grows, the brute-force
approach quickly becomes infeasible. In the classes within
sklearn.neighbors, brute-force neighbors searches are specified
using the keyword algorithm = 'brute', and are computed using the
routines available in sklearn.metrics.pairwise.
. Efficient brute-force neighbors searches can be very
competitive for small data samples.
However, as the number of samples grows, the brute-force
approach quickly becomes infeasible. In the classes within
sklearn.neighbors, brute-force neighbors searches are specified
using the keyword algorithm = 'brute', and are computed using the
routines available in sklearn.metrics.pairwise.
1.4.4.2. K-D Tree¶
To address the computational inefficiencies of the brute-force approach, a
variety of tree-based data structures have been invented. In general, these
structures attempt to reduce the required number of distance calculations
by efficiently encoding aggregate distance information for the sample.
The basic idea is that if point  is very distant from point
is very distant from point
 , and point is very close to point
, and point is very close to point  ,
then we know that points and
are very distant, without having to explicitly calculate their distance.
In this way, the computational cost of a nearest neighbors search can be
reduced to
,
then we know that points and
are very distant, without having to explicitly calculate their distance.
In this way, the computational cost of a nearest neighbors search can be
reduced to ![O[D N \log(N)]](../_images/math/d8eae1e2eb949c0aa4223ed93b3583a7cd40752e.png) or better. This is a significant
improvement over brute-force for large .
or better. This is a significant
improvement over brute-force for large .
An early approach to taking advantage of this aggregate information was
the KD tree data structure (short for K-dimensional tree), which
generalizes two-dimensional Quad-trees and 3-dimensional Oct-trees
to an arbitrary number of dimensions. The KD tree is a binary tree
structure which recursively partitions the parameter space along the data
axes, dividing it into nested orthotopic regions into which data points
are filed. The construction of a KD tree is very fast: because partitioning
is performed only along the data axes, no -dimensional distances
need to be computed. Once constructed, the nearest neighbor of a query
point can be determined with only ![O[\log(N)]](../_images/math/a6b0ef00013ae73f4b57c2019f4ca0f9f7a3646a.png) distance computations.
Though the KD tree approach is very fast for low-dimensional (
distance computations.
Though the KD tree approach is very fast for low-dimensional ( )
neighbors searches, it becomes inefficient as grows very large:
this is one manifestation of the so-called “curse of dimensionality”.
In scikit-learn, KD tree neighbors searches are specified using the
keyword algorithm = 'kd_tree', and are computed using the class
KDTree.
)
neighbors searches, it becomes inefficient as grows very large:
this is one manifestation of the so-called “curse of dimensionality”.
In scikit-learn, KD tree neighbors searches are specified using the
keyword algorithm = 'kd_tree', and are computed using the class
KDTree.
References:
- “Multidimensional binary search trees used for associative searching”, Bentley, J.L., Communications of the ACM (1975)
1.4.4.3. Ball Tree¶
To address the inefficiencies of KD Trees in higher dimensions, the ball tree data structure was developed. Where KD trees partition data along Cartesian axes, ball trees partition data in a series of nesting hyper-spheres. This makes tree construction more costly than that of the KD tree, but results in a data structure which can be very efficient on highly-structured data, even in very high dimensions.
A ball tree recursively divides the data into
nodes defined by a centroid and radius , such that each
point in the node lies within the hyper-sphere defined by and
. The number of candidate points for a neighbor search
is reduced through use of the triangle inequality:

With this setup, a single distance calculation between a test point and the centroid is sufficient to determine a lower and upper bound on the distance to all points within the node. Because of the spherical geometry of the ball tree nodes, it can out-perform a KD-tree in high dimensions, though the actual performance is highly dependent on the structure of the training data. In scikit-learn, ball-tree-based neighbors searches are specified using the keyword algorithm = 'ball_tree', and are computed using the class sklearn.neighbors.BallTree. Alternatively, the user can work with the BallTree class directly.
References:
- “Five balltree construction algorithms”, Omohundro, S.M., International Computer Science Institute Technical Report (1989)
1.4.4.4. Choice of Nearest Neighbors Algorithm¶
The optimal algorithm for a given dataset is a complicated choice, and depends on a number of factors:
number of samples
(i.e. n_samples) and dimensionality
(i.e. n_features).- Brute force query time grows as
![O[D N]](../_images/math/d8787790887d7ae2e69ac86617e5b77062d20c3e.png)
- Ball tree query time grows as approximately
![O[D \log(N)]](../_images/math/55295793640d09c237ee562bff40b9bf84a79c0d.png)
- KD tree query time changes with in a way that is difficult
to precisely characterise. For small (less than 20 or so)
the cost is approximately
![O[D\log(N)]](../_images/math/54b89f0ae345ebd679469d64633ce6334e151b1e.png) , and the KD tree
query can be very efficient.
For larger , the cost increases to nearly O[DN], and
the overhead due to the tree
structure can lead to queries which are slower than brute force.
, and the KD tree
query can be very efficient.
For larger , the cost increases to nearly O[DN], and
the overhead due to the tree
structure can lead to queries which are slower than brute force.
For small data sets (
less than 30 or so),  is
comparable to , and brute force algorithms can be more efficient
than a tree-based approach. Both KDTree and BallTree
address this through providing a leaf size parameter: this controls the
number of samples at which a query switches to brute-force. This allows both
algorithms to approach the efficiency of a brute-force computation for small
.
is
comparable to , and brute force algorithms can be more efficient
than a tree-based approach. Both KDTree and BallTree
address this through providing a leaf size parameter: this controls the
number of samples at which a query switches to brute-force. This allows both
algorithms to approach the efficiency of a brute-force computation for small
.- Brute force query time grows as
data structure: intrinsic dimensionality of the data and/or sparsity of the data. Intrinsic dimensionality refers to the dimension
 of a manifold on which the data lies, which can be linearly
or non-linearly embedded in the parameter space. Sparsity refers to the
degree to which the data fills the parameter space (this is to be
distinguished from the concept as used in “sparse” matrices. The data
matrix may have no zero entries, but the structure can still be
“sparse” in this sense).
of a manifold on which the data lies, which can be linearly
or non-linearly embedded in the parameter space. Sparsity refers to the
degree to which the data fills the parameter space (this is to be
distinguished from the concept as used in “sparse” matrices. The data
matrix may have no zero entries, but the structure can still be
“sparse” in this sense).- Brute force query time is unchanged by data structure.
- Ball tree and KD tree query times can be greatly influenced by data structure. In general, sparser data with a smaller intrinsic dimensionality leads to faster query times. Because the KD tree internal representation is aligned with the parameter axes, it will not generally show as much improvement as ball tree for arbitrarily structured data.
Datasets used in machine learning tend to be very structured, and are very well-suited for tree-based queries.
number of neighbors
requested for a query point.- Brute force query time is largely unaffected by the value of
- Ball tree and KD tree query time will become slower as
increases. This is due to two effects: first, a larger leads
to the necessity to search a larger portion of the parameter space.
Second, using
 requires internal queueing of results
as the tree is traversed.
requires internal queueing of results
as the tree is traversed.
As
becomes large compared to , the ability to prune
branches in a tree-based query is reduced. In this situation, Brute force
queries can be more efficient.- Brute force query time is largely unaffected by the value of
number of query points. Both the ball tree and the KD Tree require a construction phase. The cost of this construction becomes negligible when amortized over many queries. If only a small number of queries will be performed, however, the construction can make up a significant fraction of the total cost. If very few query points will be required, brute force is better than a tree-based method.
Currently, algorithm = 'auto' selects 'kd_tree' if  and the 'effective_metric_' is in the 'VALID_METRICS' list of
'kd_tree'. It selects 'ball_tree' if and the
'effective_metric_' is not in the 'VALID_METRICS' list of
'kd_tree'. It selects 'brute' if
and the 'effective_metric_' is in the 'VALID_METRICS' list of
'kd_tree'. It selects 'ball_tree' if and the
'effective_metric_' is not in the 'VALID_METRICS' list of
'kd_tree'. It selects 'brute' if  . This choice is based on the assumption that the number of query points is at least the
same order as the number of training points, and that leaf_size is
close to its default value of 30.
. This choice is based on the assumption that the number of query points is at least the
same order as the number of training points, and that leaf_size is
close to its default value of 30.
1.4.4.5. Effect of leaf_size¶
As noted above, for small sample sizes a brute force search can be more efficient than a tree-based query. This fact is accounted for in the ball tree and KD tree by internally switching to brute force searches within leaf nodes. The level of this switch can be specified with the parameter leaf_size. This parameter choice has many effects:
- construction time
- A larger leaf_size leads to a faster tree construction time, because fewer nodes need to be created
- query time
- Both a large or small leaf_size can lead to suboptimal query cost. For leaf_size approaching 1, the overhead involved in traversing nodes can significantly slow query times. For leaf_size approaching the size of the training set, queries become essentially brute force. A good compromise between these is leaf_size = 30, the default value of the parameter.
- memory
- As leaf_size increases, the memory required to store a tree structure
decreases. This is especially important in the case of ball tree, which
stores a -dimensional centroid for each node. The required
storage space for BallTree is approximately 1 / leaf_size times
the size of the training set.
leaf_size is not referenced for brute force queries.
1.4.5. Nearest Centroid Classifier¶
The NearestCentroid classifier is a simple algorithm that represents each class by the centroid of its members. In effect, this makes it similar to the label updating phase of the sklearn.KMeans algorithm. It also has no parameters to choose, making it a good baseline classifier. It does, however, suffer on non-convex classes, as well as when classes have drastically different variances, as equal variance in all dimensions is assumed. See Linear Discriminant Analysis (sklearn.lda.LDA) and Quadratic Discriminant Analysis (sklearn.qda.QDA) for more complex methods that do not make this assumption. Usage of the default NearestCentroid is simple:
>>> from sklearn.neighbors.nearest_centroid import NearestCentroid
>>> import numpy as np
>>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
>>> y = np.array([1, 1, 1, 2, 2, 2])
>>> clf = NearestCentroid()
>>> clf.fit(X, y)
NearestCentroid(metric='euclidean', shrink_threshold=None)
>>> print(clf.predict([[-0.8, -1]]))
[1]
1.4.5.1. Nearest Shrunken Centroid¶
The NearestCentroid classifier has a shrink_threshold parameter, which implements the nearest shrunken centroid classifier. In effect, the value of each feature for each centroid is divided by the within-class variance of that feature. The feature values are then reduced by shrink_threshold. Most notably, if a particular feature value crosses zero, it is set to zero. In effect, this removes the feature from affecting the classification. This is useful, for example, for removing noisy features.
In the example below, using a small shrink threshold increases the accuracy of the model from 0.81 to 0.82.


Examples:
- Nearest Centroid Classification: an example of classification using nearest centroid with different shrink thresholds.