SVM Exercise¶
This exercise is used in the Using kernels part of the Supervised learning: predicting an output variable from high-dimensional observations section of the Statistical-learning for scientific data processing tutorial.

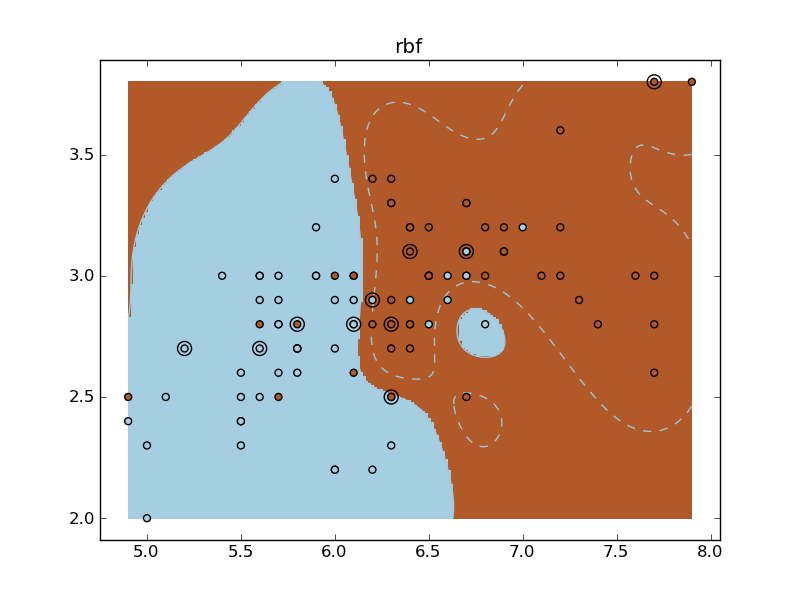
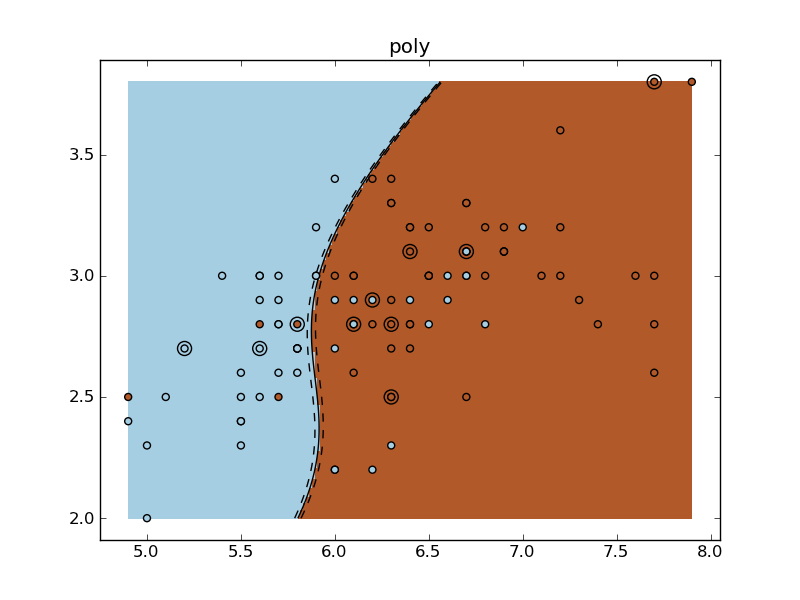
Python source code: plot_iris_exercise.py
print __doc__
import numpy as np
import pylab as pl
from scikits.learn import datasets, svm
iris = datasets.load_iris()
X = iris.data
y = iris.target
X = X[y!=0, :2]
y = y[y!=0, :2]
n_sample = len(X)
np.random.seed(0)
order = np.random.permutation(n_sample)
X = X[order]
y = y[order].astype(np.float)
X_train = X[:.9*n_sample]
y_train = y[:.9*n_sample]
X_test = X[.9*n_sample:]
y_test = y[.9*n_sample:]
h = .02 # step size in the mesh
# fit the model
for fig_num, kernel in enumerate(('linear', 'rbf', 'poly')):
pl.set_cmap(pl.cm.Paired)
clf = svm.SVC(kernel=kernel, gamma=10)
clf.fit(X_train, y_train)
pl.figure(fig_num)
pl.clf()
pl.scatter(X[:,0], X[:,1], c=y, zorder=10)
# Circle out the test data
pl.scatter(X_test[:,0], X_test[:, 1],
s=80, facecolors='none', zorder=10)
pl.axis('tight')
x_min = X[:,0].min()
x_max = X[:,0].max()
y_min = X[:,1].min()
y_max = X[:,1].max()
y_min = X[:,1].min()
y_max = X[:,1].max()
XX, YY = np.mgrid[x_min:x_max:200j, y_min:y_max:200j]
Z = clf.decision_function(np.c_[XX.ravel(), YY.ravel()])
# Put the result into a color plot
Z = Z.reshape(XX.shape)
pl.pcolormesh(XX, YY, Z > 0)
pl.contour(XX, YY, Z, colors=['k', 'k', 'k'],
linestyles=['--', '-', '--'],
levels=[-.5, 0, .5])
pl.title(kernel)