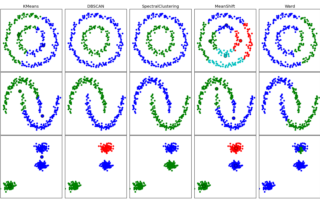
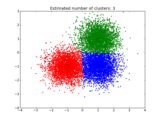
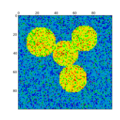
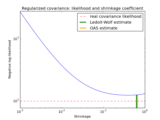
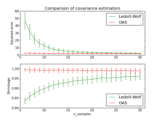
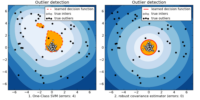
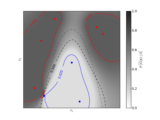
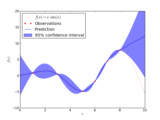
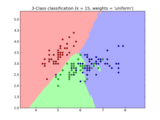
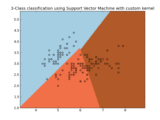
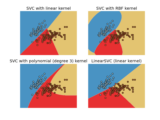
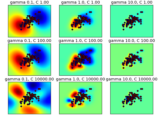
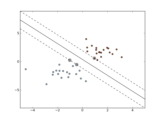
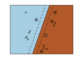
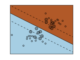
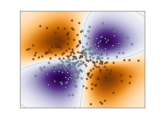
Examples¶









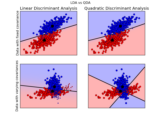






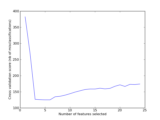









Examples based on real world datasets¶
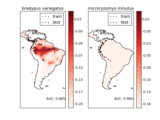
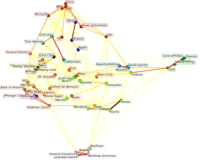
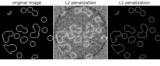
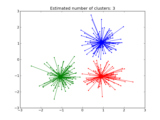
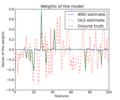
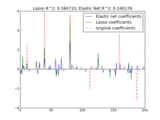
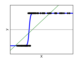
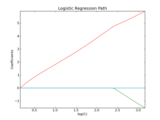
Applications to real world problems with some medium sized datasets or interactive user interface.
![]()
Applications to real world problems with some medium sized datasets or interactive user interface.