The Iris Dataset¶
This data sets consists of 3 different types of irises’ (Setosa, Versicolour, and Virginica) petal and sepal length, stored in a 150x4 numpy.ndarray
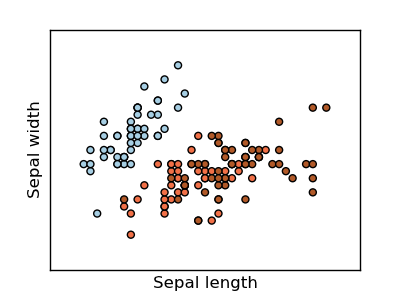
The rows being the samples and the columns being: Sepal Length, Sepal Width, Petal Length and Petal Width.
The below plot uses the first two features. See here for more information on this dataset.
Python source code: plot_iris_dataset.py
print __doc__
# Code source: Gael Varoqueux
# Modified for Documentation merge by Jaques Grobler
# License: BSD
import pylab as pl
from sklearn import datasets
# import some data to play with
iris = datasets.load_iris()
X = iris.data[:, :2] # we only take the first two features.
Y = iris.target
x_min, x_max = X[:,0].min() - .5, X[:,0].max() + .5
y_min, y_max = X[:,1].min() - .5, X[:,1].max() + .5
pl.figure(1, figsize=(4, 3))
pl.clf()
pl.set_cmap(pl.cm.Paired)
# Plot also the training points
pl.scatter(X[:,0], X[:,1], c=Y)
pl.xlabel('Sepal length')
pl.ylabel('Sepal width')
pl.xlim(x_min, x_max)
pl.ylim(y_min, y_max)
pl.xticks(())
pl.yticks(())
pl.show()